[ad_1]
Saat saya mulai bekerja dengan AWS SageMaker, salah satu pertanyaan paling umum adalah: “Jenis inferensi manakah yang harus saya pilih untuk model saya?” SageMaker menawarkan empat opsi berbeda, dan pada pandangan pertama, perbedaan di antara keduanya tidak selalu terlihat jelas. Mari kita uraikan kapan dan pendekatan mana yang digunakan.
Apa itu Payload dan Mengapa Itu Penting?
Sebelum mendalami jenis inferensi, penting untuk memahami istilah tersebut Muatan — ini adalah ukuran data yang Anda kirim ke model untuk diproses. Misalnya:
-
Untuk mengklasifikasikan satu gambar berukuran 224×224 piksel dalam format JSON – sekitar 150 KB
-
Untuk menganalisis dokumen teks 10 halaman – sekitar 50–100 KB
-
Untuk memproses sebuah fragmen video – ukurannya bisa puluhan atau ratusan megabyte
Jenis inferensi yang berbeda memiliki batasan payload yang berbeda karena secara arsitektural mereka memecahkan masalah yang berbeda: beberapa dioptimalkan untuk respons cepat dengan data kecil, yang lain untuk pemrosesan volume besar dalam jangka waktu lama.
Inferensi Waktu Nyata: Untuk Respons Instan
Spesifikasi Teknis:
-
Muatan:hingga 25 MB
-
Waktu pengerjaan:Â hingga 60 detik (8 menit untuk streaming)
-
Saatnya mulai memproses:Â instan (titik akhir sudah berjalan)
-
Manajemen instans:Â Anda secara manual memilih jenis dan jumlah instance (misal, ml.m5.xlarge)
-
Model penetapan harga:Â membayar misalnya uptime 24/7, berapa pun volume permintaan
-
Titik akhir persisten:Â REST API selalu tersedia
Kapan menggunakan:Â Inferensi real-time adalah pilihan Anda untuk aplikasi produksi di mana pengguna mengharapkan respons segera.
Contoh praktis:Â Sistem rekomendasi e-commerce. Saat pengguna melihat suatu produk, Anda harus langsung menampilkan rekomendasi yang dipersonalisasi. Bahkan penundaan beberapa detik pun dapat menyebabkan hilangnya konversi. Titik akhir real-time memproses setiap permintaan dalam milidetik dan dapat diskalakan untuk menangani ribuan pengguna secara bersamaan.
Catatan penting:Â Anda membayar instans terus-menerus, bahkan ketika tidak ada permintaan. Misalnya, jika Anda meluncurkan ml.m5.xlarge ($0,23/jam), Anda akan membayar sekitar $166 per bulan, meskipun tidak ada permintaan di akhir pekan.
Inferensi Tanpa Server: Hanya Bayar untuk Penggunaan
Spesifikasi Teknis:
-
Muatan:Â hingga 4 MB (lebih kecil karena arsitektur tanpa server)
-
Waktu pengerjaan:hingga 60 detik
-
Saatnya mulai memproses:
Cold start (permintaan pertama): 10–30 detik (SageMaker memutar sebuah instance) Warm start (permintaan berikutnya): instan (jika instance masih aktif)Â Penting:Â Mesin bersuhu hangat beralih ke mesin dingin setelah sekitar 10–15 menit tidak ada aktivitas
-
Manajemen instans:Â sepenuhnya otomatis, Anda tidak mengelola instance
-
Model penetapan harga:Â hanya membayar waktu pemrosesan permintaan (dalam milidetik) + volume memori
-
Penskalaan otomatis:Â dari 0 hingga jumlah instans yang diperlukan
Kapan menggunakan:Â Ideal untuk lalu lintas yang tidak dapat diprediksi atau ketika layanan Anda digunakan secara tidak teratur.
Contoh praktis:Â Alat internal untuk analisis kontrak di firma hukum. Pengacara mengunggah dokumen beberapa kali sehari, tetapi tidak terus-menerus. Dengan inferensi tanpa server, Anda tidak perlu membayar untuk kejadian menganggur di malam hari atau di akhir pekan. Saat permintaan masuk, SageMaker secara otomatis mengalokasikan sumber daya, memproses dokumen, dan melepaskannya.
Catatan penting:Â Permintaan pertama setelah waktu idle akan memakan waktu 10–30 detik (cold start), yang penting untuk dipertimbangkan demi pengalaman pengguna. Jika layanan Anda menerima permintaan kurang dari sekali setiap 10–15 menit, setiap permintaan akan mengalami cold start. Anda membayar untuk waktu eksekusi sebenarnya – jika pemrosesan memerlukan waktu 2 detik, Anda hanya membayar untuk 2 detik tersebut.
Transformasi Batch: Pemrosesan Data Massal
Spesifikasi Teknis:
-
Muatan:Â kumpulan data berukuran gigabyte (hampir tanpa batas)
-
Waktu pengerjaan:Â dari menit ke hari
-
Saatnya mulai memproses:Â 5–10 menit (waktu untuk meluncurkan instance dan memuat model)
-
Manajemen instans:Â Anda menentukan jenis dan jumlah instans untuk pekerjaan tersebut
-
Model penetapan harga:Â membayar hanya untuk waktu pelaksanaan pekerjaan batch (dari awal hingga selesai)
-
Tidak ada titik akhir yang persisten:Â instance dibuat untuk tugas tersebut dan dihapus setelah selesai
Kapan menggunakan:Â Saat Anda perlu memproses data dalam jumlah besar dan waktu eksekusi tidaklah penting.
Contoh praktis:Â Pemrosesan gambar setiap malam untuk moderasi konten. Anda memiliki 100.000 gambar yang diunggah oleh pengguna sepanjang hari yang perlu diperiksa apakah ada pelanggaran. Luncurkan tugas transformasi batch pada pukul 02.00 dengan 5 instans ml.p3.2xlarge, yang memproses semua gambar dalam 3 jam, menyimpan hasilnya ke S3, dan dihentikan secara otomatis. Anda hanya membayar untuk 3 jam kerja ini x 5 instance = 15 jam instance.
Catatan penting:Â Tidak ada batasan ukuran payload, karena data dibaca secara batch dari S3. Transformasi Batch hemat biaya untuk volume besar karena instans dihapus secara otomatis setelah selesai.
Inferensi Asinkron: Untuk Tugas Berat
Spesifikasi Teknis:
-
Muatan:Â hingga 1 GB (ukuran besar karena data diunggah melalui S3)
-
Waktu pengerjaan:hingga 1 jam per permintaan
-
Saatnya mulai memproses:
-
Jika endpoint aktif: instan (permintaan masuk ke antrian)
-
Jika titik akhir berada pada 0: 2–5 menit (waktu untuk meningkatkan skala)
-
Manajemen instans:Â Anda memilih jenis instans dan mengonfigurasi penskalaan otomatis (termasuk skala ke nol)
-
Model penetapan harga:Â membayar uptime misalnya, tetapi dapat mengonfigurasi skala ke nol ketika tidak ada permintaan
-
Antrian permintaan:Â sistem antrian bawaan (Amazon SQS)
Kapan menggunakan:Â Untuk tugas yang memerlukan sumber daya komputasi dan waktu yang signifikan.
Contoh praktis: Pembuatan video AI. Pengguna mengunggah parameter untuk membuat animasi 3D atau presentasi video. Prosesnya dapat memakan waktu 20–40 menit. Dengan inferensi asinkron, permintaan ditempatkan dalam antrean, pengguna menerima ID notifikasi, dan ketika pemrosesan selesai — webhook akan memberi tahu frontend. Jika tidak ada permintaan selama lebih dari 15 menit, titik akhir secara otomatis menskalakan ke 0, sehingga menghemat anggaran Anda.
Catatan penting:Â Anda membayar untuk waktu instans aktif. Jika Anda mengonfigurasi skala ke nol dengan periode menganggur 15 menit, dan permintaan datang satu kali per jam, dari 24 jam Anda akan membayar sekitar 2–3 jam kerja sebenarnya + 15 menit waktu menganggur setelah setiap permintaan.
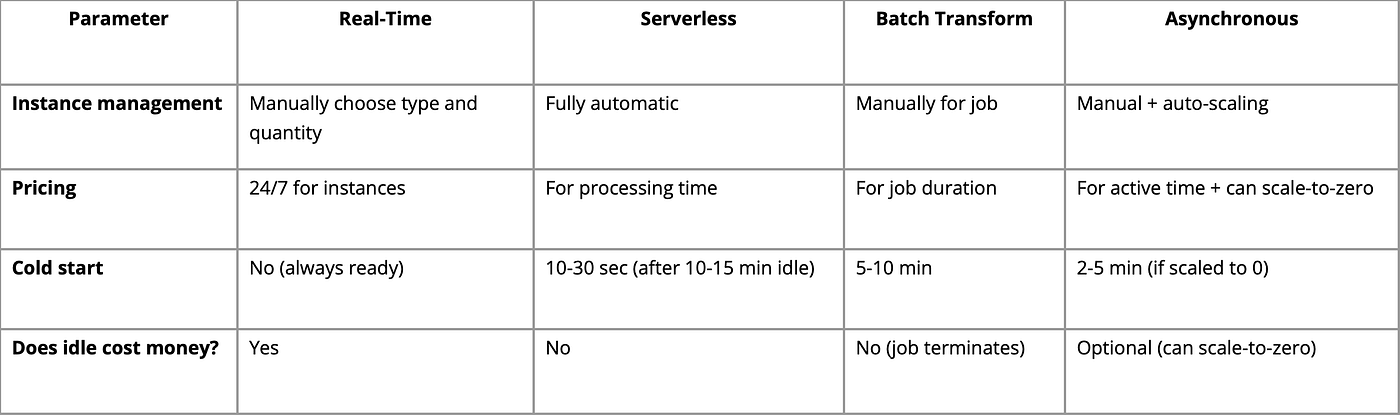
Tabel Perbandingan: Manajemen dan Penetapan Harga

Bagaimana Cara Memilihnya?
Tanyakan pada diri Anda empat pertanyaan:
1. Berapa lama pengguna bersedia menunggu tanggapan?
-
Milidetik/detik â†' Waktu Nyata
-
Beberapa detik (bersedia menunggu) â†' Tanpa server
-
Menit/jam â†' Asinkron
-
Tidak masalah â†' Transformasi Batch
2. Bagaimana pola lalu lintasnya?
-
Konstan, dapat diprediksi â†' Real-Time
-
Tidak dapat diprediksi/jarang â†' Tanpa Server
-
Berkala (sekali sehari/minggu) â†' Transformasi Batch
-
Beban puncak dengan pemrosesan yang lama â†' Asinkron
3. Berapa ukuran datanya?
-
<4 MB â†' opsi apa pun
-
4–25 MB â†' Real-Time atau Asinkron
-
25 MB — 1 GB â†' Asinkron
-
1 GB â†' Transformasi Batch
4. Apakah Anda bersedia membayar untuk waktu menganggur?
-
Ya, memerlukan kecepatan maksimal â†' Real-Time
-
Tidak, lalu lintas tidak teratur â†' Tanpa Server atau Asinkron (skala ke nol)
-
Tidak, tugas berkala â†' Transformasi Batch
Kesimpulan
Memilih jenis inferensi yang tepat di SageMaker dapat berdampak signifikan terhadap performa layanan ML Anda dan biaya infrastruktur. Memahami perbedaan dalam manajemen instans dan model penetapan harga adalah kunci pengoptimalan biaya. Tidak ada solusi universal — menganalisis kebutuhan Anda untuk latensi, volume, frekuensi, dan memilih opsi optimal. Dan hal itu sangat penting di beberapa proyek, Anda mungkin memerlukan kombinasi beberapa jenis untuk kasus penggunaan yang berbeda.
[ad_2]
Memilih Jenis Inferensi yang Tepat untuk Model ML / Habr



